Data Lake Architecture: Design Principles and Best Practices
Minutes Read
In the ever-evolving world of big data, businesses are increasingly relying on sophisticated systems to collect, store, and analyse vast amounts of information. One of the most effective solutions for managing this data explosion is the Data Lake—a centralised repository that allows organisations to store structured, semi-structured, and unstructured data at any scale. In this blog, we will explore data lake architectures, the core design principles, and the best practices that ensure optimal performance, scalability, and data governance. Additionally, we'll touch on how enterprise data lake services, data lake solutions, and enterprise data lake consulting services can help businesses implement and optimise their data lakes.
What is a Data Lake?
A data lake is a storage system that holds large amounts of raw data in its native format until needed. Unlike traditional databases or data warehouses, which require data to be formatted and cleaned before storage, data lakes allow for schema-on-read. This means data is only processed and structured when it is accessed, making it highly flexible for various analytics workloads. Data lakes are a core component of many enterprise data lake solutions because they can support a wide range of analytics processes, from machine learning and predictive analytics to business intelligence and data visualisation.
Why Businesses Choose Data Lakes
1) Scalability
Data lakes offer unlimited scalability, allowing businesses to store petabytes or even exabytes of structured, semi-structured, and unstructured data. Whether you're seeking data lake solutions in India or globally, data lakes are ideal for managing massive data volumes. As enterprises anticipate exponential data growth, they increasingly turn to enterprise data lake services to future-proof their operations.
2) Flexibility
Unlike traditional databases or data warehouses, data lakes support a wide range of data formats such as CSV, JSON, XML, Parquet, ORC, and others. This flexibility allows organisations to store raw, processed, or even semi-processed data from multiple sources, making it easier to experiment with data science and machine learning models.
3) Cost Efficiency
Data lakes are built using cloud storage solutions, which provide pay-as-you-go pricing models, helping businesses significantly reduce upfront infrastructure costs. By partnering with a data lake consulting solution firm, organisations can move cold data to low-cost storage, further optimising operational expenses.
4) Agility
With data lakes, businesses can ingest and store data immediately without the need for upfront structuring or transformations. This means that data can be explored in its raw format, making data lakes particularly useful for ad-hoc queries, exploratory data analysis, and evolving data-driven decision-making.
5) Future-Proofing
As more organisations adopt AI and machine learning in their operations, the flexibility and scalability of data lakes make them a future-proof investment. Enterprise data lake consulting can help organisations stay competitive by supporting advanced analytics, real-time data streaming, and predictive modelling.
Bonus Points: Data lake consulting plays a crucial role in enabling AI and machine learning (ML) solutions by streamlining data management and storage. With large volumes of structured and unstructured data flowing into organizations, data lakes provide a flexible and scalable environment for data processing. This helps in faster data preparation, improving the accuracy and efficiency of AI and ML models. Leveraging data lake consulting allows businesses to optimize their data infrastructure, ensuring better decision-making and innovation in AI-driven projects. For more details, visit 👉 Unlocking AI and ML Potential Through Data Lake Consulting.
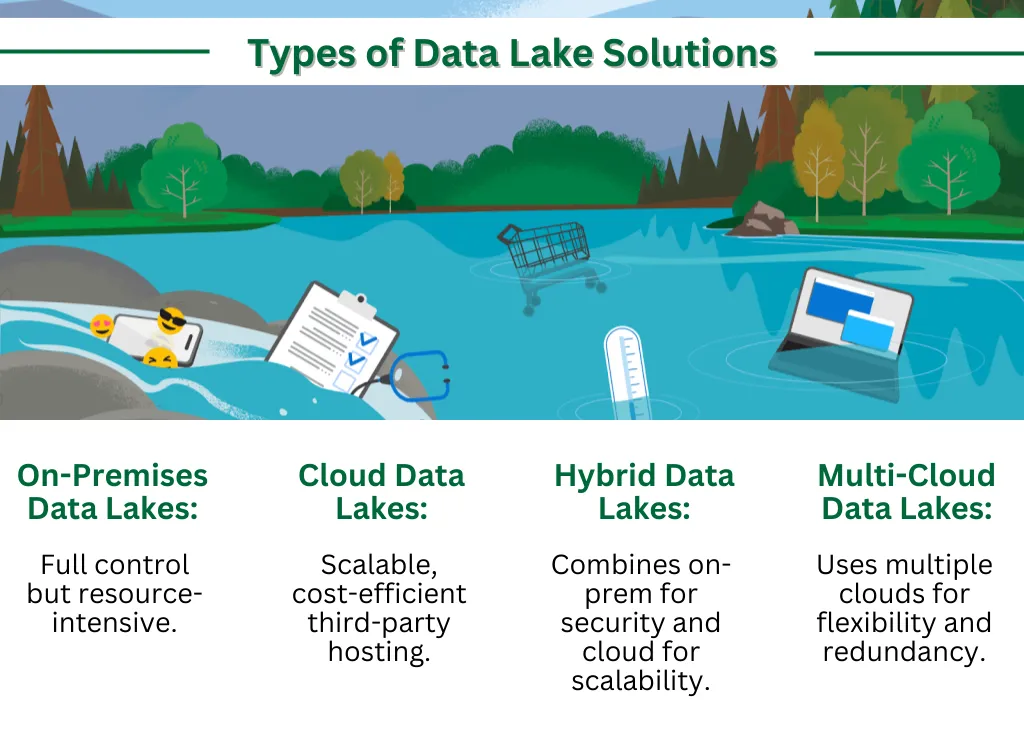
Types of Data Lake Solutions
1) On-Premises Data Lakes
An on-premises data lake provides full control over your data storage infrastructure. This solution is commonly chosen by organisations with strict data governance, security, or compliance requirements. However, managing an on-prem data lake can be resource-intensive, requiring a significant investment in hardware, software, and IT staff to maintain and scale the system.
2) Cloud Data Lakes
Cloud-based data lakes are hosted by third-party providers such as AWS, Microsoft Azure, and Google Cloud. These solutions offer high scalability, availability, and cost efficiency through a pay-as-you-go model. Cloud data lakes consulting services can help businesses implement and maintain cloud data lakes while ensuring integration with cloud-based analytics tools.
3) Hybrid Data Lakes
A hybrid data lake architecture combines on-premises and cloud resources, allowing businesses to enjoy the benefits of both environments. For example, sensitive data can remain on-prem for security and compliance, while less sensitive data is stored in the cloud for cost optimisation and scalability.
4) Multi-Cloud Data Lakes
Multi-cloud data lake solutions leverage multiple cloud providers to store and manage data across different platforms. This approach offers businesses the flexibility to choose the best provider for specific use cases (e.g., AWS for machine learning and Google Cloud for data analytics) and to reduce risks associated with vendor dependency. It also enhances business continuity by ensuring data is stored redundantly across multiple cloud environments.
Reliable Tools for Building a Data Lake Solutions
1. Apache Hadoop
A foundational framework for building distributed data lakes, Hadoop enables businesses to store and process vast amounts of data across multiple nodes. It supports various file systems, including HDFS and S3, making it essential for enterprise data lake servicesthat need both batch processing andreal-time analytics.
2. AWS Lake Formation
AWS Lake Formation simplifies the setup of secure data lakes on AWS. This service helps businesses easily ingest, catalog, and secure data from multiple sources, streamlining the creation of a governed data lake. It also integrates well with AWS analytics tools such as AWS Glue, Redshift, and Athena. If you're using any ELT tools, than this may easily integrates with best ELT tools for AWS.
Built on Apache Spark, Databricks is a unified analytics platform that provides an integrated environment for data engineering, machine learning, and business analytics. It is widely used in data lake consulting for building collaborative data pipelines, performing real-time data analysis, and training machine learning models on big data.
4. Azure Data Lake Storage (ADLS)
Azure’s ADLS is a highly scalable data lake storage solution that integrates seamlessly with other Microsoft services such as Azure Data Factory, Power BI, and Synapse Analytics. It provides tiered storage for cost optimisation, robust security and governance features, such as RBAC and encryption, making it a key component for cloud data lake consulting services.
5. Google Cloud Storage
Google Cloud provides secure and scalable data lake storage via Cloud Storage, which is optimised for both cold and hot data workloads. Paired with tools like BigQuery for real-time analytics and TensorFlow for machine learning, Google Cloud is a popular choice for organisations leveraging advanced analytics.
Key Design Principles for Building a Data Lake
To build an effective data lake, following these design principles is essential:
1. Data Ingestion and Integration
Ensure your data lake can ingest data from multiple sources, such as databases, sensors, applications, and streaming platforms. Batch and real-time streaming data ingestion (e.g., from Apache Kafka, is an open-source circulated streaming framework utilised for stream handling: exploring Apache Kafka and its benefits) should be supported to handle both structured and unstructured data.
Additionally, it’s crucial to ensure proper data integration pipelines that enable data from various sources to be seamlessly transformed and enriched for downstream analytics.
2. Storage Layer Optimisation
The storage layer forms the backbone of a data lake. It should be designed to be:
Scalable: The architecture must be able to store massive datasets as the business grows.
Cost-efficient: Use tiered storage options (hot, warm, cold) to store frequently accessed data in higher-performance storage tiers while archiving less-used data in lower-cost storage.
Durable: Data must be stored in redundant, highly available systems to prevent data loss.
Cloud storage options such as Amazon S3, Azure Blob Storage, or Google Cloud Storage are widely used to implement cost-effective, scalable storage layers, a common recommendation by enterprise data lake solutions providers.
3. Data Governance and Security
Data governance is a key consideration in ensuring data quality, security, and compliance in a data lake. Adopt a comprehensive data governance framework that includes:
Metadata management: Use tools like Apache Atlas or AWS Glue Data Catalog to manage metadata, making it easier to search and access data.
Data cataloging: Implement data catalogs to classify data and ensure it’s discoverable by analysts and data scientists.
Access control and encryption: Use role-based access controls (RBAC) and encrypt data both in transit and at rest to prevent unauthorized access.
Compliance: Ensure compliance with GDPR, HIPAA, or other regulatory standards by implementing fine-grained access controls and data masking techniques.
4. Data Processing and Analytics
Data lakes should support multi-modal analytics that allow for processing structured and unstructured data alike. Key technologies include:
Batch processing using Apache Hadoop or Apache Spark for processing large data volumes.
Real-time analytics using stream processing tools like Apache Flink or AWS Kinesis for real-time data insights.
Querying capabilities with SQL-on-Hadoop tools such as Presto or Amazon Athena to enable ad hoc querying of large datasets without the need for ETL (Extract, Transform, Load).
5. Performance and Scalability
To maintain optimal performance, partitioning and indexing data within your lake is crucial. Leverage columnar file formats like Apache Parquet or ORC to store large datasets, as these formats allow for faster query times and more efficient storage.
Implement autoscaling in cloud environments to dynamically scale storage and compute resources based on usage, ensuring the system remains performant even under high demand.
6. Monitoring and Maintenance
Data lakes require continuous monitoring to ensure performance and cost efficiency. Use monitoring tools like AWS CloudWatch, Azure Monitor, or open-source alternatives like Prometheus to track the health of your storage and processing layers.
Automate routine maintenance tasks such as data purging or archiving with tools like Apache Airflow or AWS Step Functions, reducing the operational overhead on your IT teams.
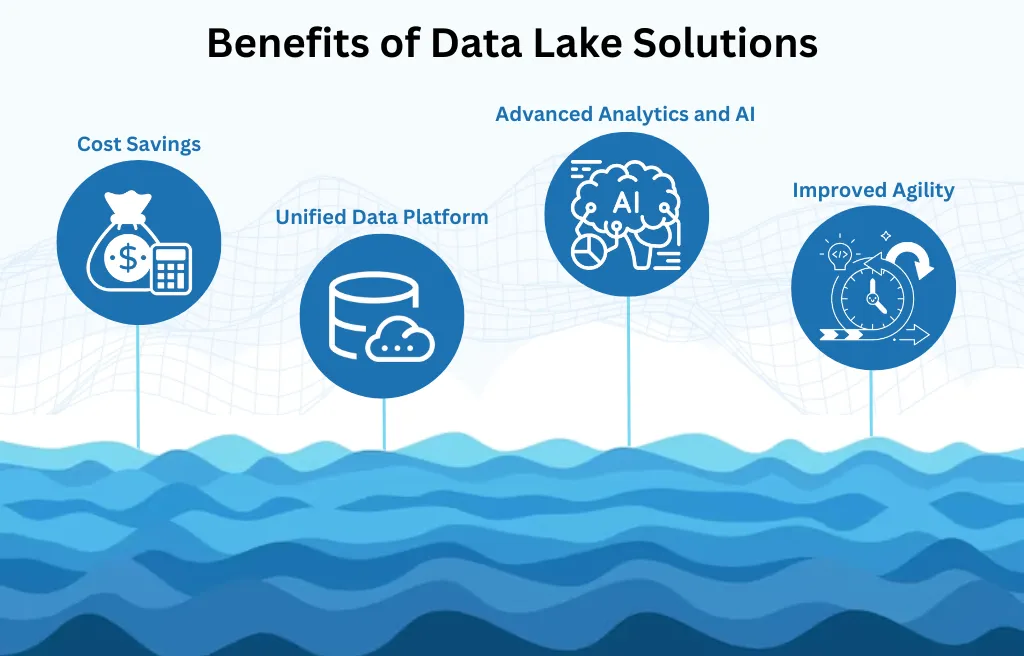
Benefits of Data Lake Design
1. Cost Savings
A data lake allows businesses to store large volumes of raw data at a low cost, bypassing the need for expensive ETL processes required by traditional data warehouses. Suggested by top data lake solution firms, organisations can process data on-demand, which helps reduce upfront infrastructure costs and transformation expenses.
2. Unified Data Platform
Data lakes act as a centralised repository where all types of data can be stored—structured, semi-structured, and unstructured. This enables organisations to manage diverse data sources (e.g., CRM systems, IoT devices, social media platforms) under a single architecture, simplifying data analytics and reporting.
3. Advanced Analytics and AI
Data lakes are designed to support advanced analytics such as machine learning, AI, predictive modeling, and deep learning. By storing historical and real-time data together, businesses can generate insights that drive innovation, personalization, and predictive capabilities. Moreover, integrating data lakes with data visualization tools enables businesses to create interactive dashboards and visually rich reports. With the help of data visualization consulting services, organizations can customize these visualizations to better understand complex data patterns, identify trends, and enhance data-driven decision-making. This combination of advanced analytics and data visualization solutions empowers decision-makers to monitor performance, communicate insights clearly, and drive strategic actions with more confidence.
4. Improved Agility
With data lakes, businesses can quickly respond to new data sources or evolving business needs without the need for rigid data preparation or ETL processes. This agility allows for faster innovation and quicker decision-making.
In the world of data management, three distinct architectures have emerged as prominent solutions: Data Lakes, Data Warehouses, and Data Lakehouses. Each architecture serves different purposes and is suited for different types of workloads. Below, we'll explore their differences, use cases, and how they fit into modern data strategies.
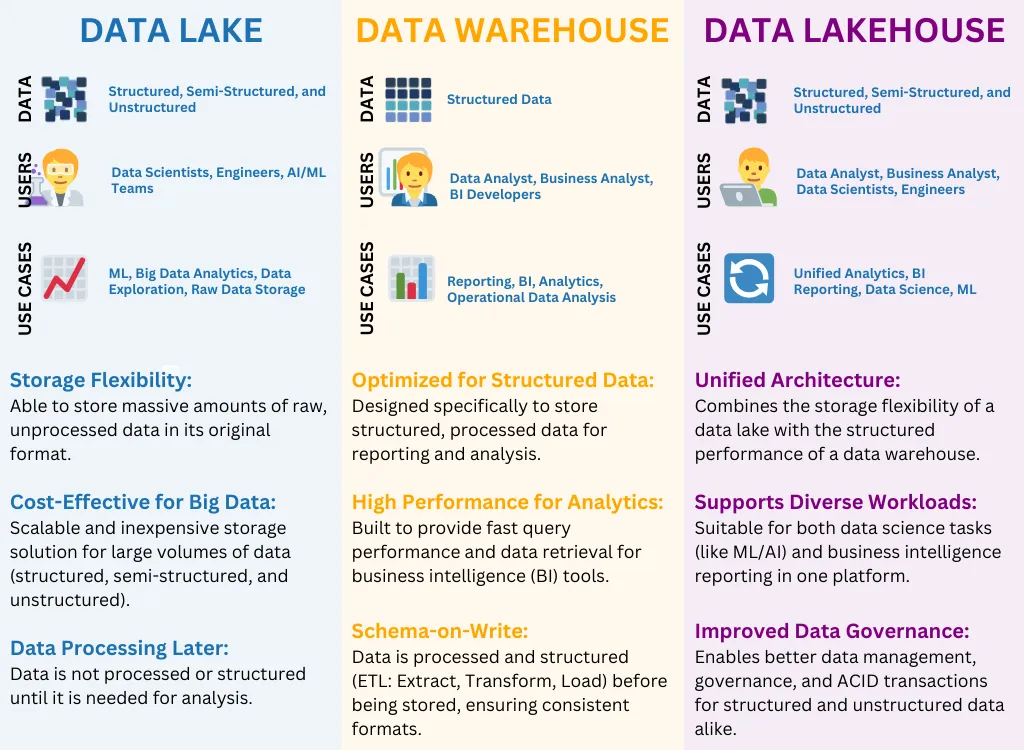
Data Lake
A Data Lake is a centralized repository that allows organizations to store vast amounts of raw, unstructured, semi-structured, and structured data. It can scale to handle petabytes or even exabytes of data, with the flexibility to ingest data in its native format, such as text files, logs, images, videos, and more.
Key Characteristics of Data Lake
Schema-on-Read: Data is stored in its raw form and only structured when it's accessed or queried. This enables flexibility, allowing for diverse use cases.
Supports All Data Types: Structured, semi-structured, and unstructured data can be stored in the same environment.
Scalability: Easily scales to accommodate growing data volumes, making it ideal for large datasets.
Low-Cost Storage: Typically implemented using cloud storage, which offers tiered pricing models for cold and hot data.
Use Cases of Data Lake
Machine Learning & AI: Storing raw data for model training and experimentation.
Big Data Analytics: Analyzing massive datasets with varying formats.
Machine Learning & AI: Storing raw data for model training and experimentation.
Real-time Data Ingestion: Ingesting data from IoT devices, sensors, and log files for immediate or future use.
Challenges of Data Lake
Data Governance: Without proper governance, data lakes can turn into "data swamps," where data becomes disorganized and difficult to manage.
Lack of Structured Querying: Querying raw data in a data lake can be inefficient, requiring specialized tools.
Data Warehouse
A Data Warehouse is a highly structured and optimized environment designed for storing large amounts of organized, processed data, typically in a relational database format. It is part of comprehensive data warehouse services, which are ideal for running complex queries and producing business intelligence reports from structured data.
Schema-on-Write: Data is transformed, cleaned, and structured before it is loaded into the warehouse, ensuring high data quality.
Optimized for Analytics: Designed for running complex SQL queries and generating business intelligence reports.
Structured Data: Primarily stores structured and processed data from transactional databases and business applications.
High Performance: Data warehouses are optimized for query performance, making them ideal for large-scale reporting and analysis.
Use Cases of Data Warehouse
Business Intelligence (BI): Running reports and dashboards for decision-making is a major use case for data warehouse implementation.
Historical Data Analysis: Analyzing long-term trends and patterns from historical datasets.
Enterprise Reporting: Centralized reporting from various business systems.
Challenges of Data Warehouse
Cost: Data warehouses are typically more expensive due to the high-performance infrastructure required. However, it is also recommended to incorporate it for structured data, as advised by top data warehouse consulting firms.
Data Flexibility: Data warehouses are less flexible for unstructured or semi-structured data and require data to be processed and structured before storage.
Data Lakehouse
The Data Lakehouse is a relatively new architecture that aims to combine the best features of both data lakes and data warehouses. It allows data lake solution experts to leverage both the flexibility of data lakes (handling raw and unstructured data) and the performance and structure of data warehouses (enabling faster querying of structured data).
Key Characteristics of Data Lakehouse
Unified Storage: Combines the raw data storage capabilities of data lakes with the query optimization features of data warehouses.
Schema-on-Read and Schema-on-Write: Supports both raw data ingestion and structured querying, providing a balance between flexibility and performance.
Support for Structured, Semi-Structured, and Unstructured Data: Like a data lake, it can store multiple data formats but also offers performance for structured queries.
ACID Transactions: Supports atomic, consistent, isolated, and durable (ACID) transactions, which are essential for data reliability and governance.
Use Cases of Data Lakehouse
Hybrid Workloads: Running both advanced analytics (e.g., machine learning, data science) and business intelligence queries.
Data Democratization: Allowing different teams to access both raw and processed data for various use cases.
Real-time Analytics: Combining real-time data ingestion and fast querying for time-sensitive insights.
Challenges of Data Lakehouse
Complexity: Implementing a data lakehouse can be more complex due to the need for both real-time processing and high-performance querying.
Relatively New: The data lakehouse architecture is still evolving, and its long-term effectiveness in various industries is being tested.
Details:
Data Lakes are best for flexibility and scalability, especially when dealing with raw, unstructured data. However, they can become unmanageable without proper governance.
Data Warehouses are ideal for structured data and business intelligence use cases, but they are costly and less flexible for evolving data formats.
Data Lakehouses offer a blend of both, providing flexibility in storing diverse data formats while ensuring fast, reliable analytics for decision-making, though they come with added complexity.
Core Data Lake Architectures
When designing a data lake solution, it’s crucial to consider the architecture, which can vary depending on the use case and business requirements. Here are three core architectures commonly used:
1. Centralized Data Lake Architecture
In a centralized architecture, all data from different business units or departments is stored in a single, unified data lake. This type of architecture is ideal for organisations that want to manage all their data from a single repository, making it easier to perform enterprise-wide analytics.
Pros of Data Lake Architecture
Unified access to data
Simplified governance and security
Easier integration with AI/ML pipelines
Cons of Data Lake Architecture
Higher risk of data silos if not governed properly
Single point of failure for the entire organisation
Organisations often rely on enterprise data lake consulting services to design centralized architectures that align with their business goals and security needs.
2. Decentralized Data Lake (Federated Data Lake)
In a decentralized architecture, each department or business unit manages its own data lake. This approach is popular in large enterprises where different teams require autonomy over their data while still benefiting from the scalability of a data lake.
Pros of Decentralized Data Lake
Each business unit can have specialized governance and security policies
Reduces bottlenecks in managing large-scale data
Better control over data lineage within departments
Cons of Decentralized Data Lake
Can lead to data silos without a strong data integration strategy
Complexity in achieving enterprise-wide insights
To navigate the complexity of decentralized architectures, businesses frequently leverage enterprise data lake services to ensure effective governance and seamless integration between department-specific data lakes.
3. Multi-Cloud and Hybrid Data Lake Architectures
Organisations adopting cloud strategies may deploy multi-cloud or hybrid data lake architectures. In this setup, a portion of the data lake is hosted on-premises while another part resides in a cloud provider. Alternatively, multiple clouds may be used depending on cost, data residency, or compliance needs.
Pros of Multi-Cloud and Hybrid Data Lake Architectures
Flexibility in managing sensitive data across regions or clouds
Reduces vendor lock-in by spreading workloads across multiple platforms
Better disaster recovery capabilities
Cons of Multi-Cloud and Hybrid Data Lake Architectures
Higher complexity in managing data integration, security, and governance across platforms
Potential latency issues when querying cross-cloud data
Organisations often engage enterprise data lake consulting services to implement robust hybrid architectures and ensure seamless multi-cloud data integration.
Without proper governance and metadata management, data lakes can turn into data swamps, where data becomes disorganized, difficult to access, and largely unusable. To prevent this, businesses must implement metadata catalogs, data quality controls, and a robust data governance framework.
2. Security and Compliance Risks
Due to the large volumes of sensitive data stored in data lakes, they are attractive targets for cyberattacks. Ensuring data is encrypted both at rest and in transit, applying role-based access controls (RBAC), and adhering to compliance regulations like GDPR and HIPAA are critical to securing your data lake.
3. Data Quality Management
As the volume of data grows, maintaining data quality becomes increasingly difficult. Implementing regular data validation, cleansing processes, and schema-on-read approaches can help avoid issues related to inconsistent, incomplete, or incorrect data.
4. Operational Complexity
Building and maintaining a data lake requires expertise in cloud architecture, data governance, and data engineering. Operational challenges include managing multiple data sources, ensuring performance optimisation, and reducing latency in query times.
Data Lakes Use Cases
Data lakes provide flexibility and scalability that enable businesses across industries to efficiently store, manage, and analyze large volumes of diverse data. Below are some prominent use cases that demonstrate how organizations can leverage data lakes to drive innovation and achieve business objectives:
1. Healthcare
Data lakes in healthcare facilitate the storage and analysis of vast datasets, including patient records, medical images, genomic data, and data from healthcare IoT devices. By integrating these diverse data sources, healthcare organisations can:
Enhance patient care by providing comprehensive data for personalized treatment plans.
Accelerate medical research by storing large-scale clinical trial data, enabling faster drug discovery and development.
Improve predictive analytics for identifying disease outbreaks, managing chronic diseases, and optimizing hospital resource allocation.
Ensure compliance with regulatory standards like HIPAA by implementing strong data governance and security frameworks.
2. Retail and E-Commerce
In the fast-paced world of retail, data lakes allow companies to store and analyze a wide range of data, including transactional data, customer behavior, social media interactions, and inventory data. Retailers can leverage data lakes to:
Personalize customer experiences by using historical shopping behavior, product preferences, and browsing patterns to recommend products in real time.
Optimize inventory management by analyzing sales trends, seasonal patterns, and supply chain logistics, reducing stockouts and overstocking.
Develop advanced pricing strategies through dynamic pricing models based on competitor data, market trends, and customer demand.
Improve targeted marketing and advertising efforts by segmenting customers based on demographic and behavioral data.
3. Finance and Banking
Data lakes are pivotal in the financial services sector, where businesses deal with massive datasets from multiple sources, including transactional systems, market data, social media, and customer profiles. Financial institutions use data lakes to:
Enhance fraud detection by analyzing transaction patterns, customer behavior, and third-party data in real time to detect anomalies and potential fraud.
Improve risk management by consolidating data from different departments, enabling advanced risk modeling, credit scoring, and portfolio analysis.
Drive regulatory compliance by storing and managing data in a format that allows easy access and auditing, ensuring adherence to regulatory requirements like SOX, GDPR, and CCAR.
Power predictive analytics for investment strategies, enabling data-driven financial decision-making and improving customer service.
4. Manufacturing and Industrial IoT
Manufacturers can use data lakes to consolidate and analyze data from production lines, machine sensors, IoT devices, and supply chain systems. These data lakes support:
Predictive maintenance by identifying potential equipment failures before they happen, reducing downtime and saving costs.
Process optimization through real-time data analysis from sensors on factory floors, enabling better production control and quality assurance.
Supply chain optimization by analyzing logistics data, inventory levels, and market demand to streamline production and reduce inefficiencies.
Facilitating smart manufacturing with AI-powered analytics, helping manufacturers embrace Industry 4.0 and create more agile production environments.
Data lakes help media companies aggregate and analyze large amounts of content, audience data, and user interactions across multiple platforms. This allows them to:
Offer personalized content recommendations by analyzing user preferences, viewing habits, and engagement metrics across different platforms.
Improve advertising strategies by integrating customer data from various sources to create highly targeted, data-driven advertising campaigns.
Analyze content performance to understand what types of content drive the most engagement and optimize content production and distribution.
Store and manage large-scale media assets, including videos, images, and audio files, enabling efficient media workflows.
6. Energy and Utilities
Energy companies leverage data lakes to store and analyze data from smart meters, energy grids, and renewable energy sources. This allows them to:
Optimize energy distribution and demand forecasting by analyzing consumption patterns in real time, leading to better load balancing and energy efficiency.
Enhance renewable energy integration by analyzing data from wind, solar, and hydropower sources to maximize renewable energy production.
Improve asset management and predictive maintenance of power plants, grids, and equipment, ensuring operational efficiency and reducing the risk of outages.
Analyze environmental data to support sustainability efforts and reduce carbon footprints by leveraging data-driven insights for cleaner energy production.
7. Government and Public Sector
Government agencies use data lakes to centralize vast amounts of data from citizen services, public safety, transportation, and emergency response systems. These agencies can:
Use real-time data analytics for faster and more informed decision-making during emergencies, such as natural disasters, by aggregating data from multiple sources.
Improve public safety by analyzing data from surveillance systems, social media, and criminal databases to predict and prevent criminal activity.
Enhance policy-making by analyzing public data trends, citizen feedback, and economic metrics to inform decisions and improve government services.
Streamline citizen services through better data integration, enabling more efficient handling of healthcare, education, and welfare programs.
8. Telecommunications
Telecom companies use data lakes to analyze vast amounts of network data, customer usage patterns, and service performance metrics. They can:
Improve network performance by analyzing real-time data from sensors and devices, identifying bottlenecks, and predicting outages before they happen.
Enhance customer satisfaction by providing personalized services and offers based on usage data, preferences, and churn analysis.
Drive 5G implementation by analyzing network data in real-time, optimizing resource allocation, and ensuring smooth deployment of next-gen technologies.
Data Lake Adoption Trends
1. Growth in Adoption:
Over 60% of organizations were using data lakes for analytics by 2022 (Gartner).
2. Cloud Shift:
57% of data lakes are now cloud-based due to benefits like scalability and reduced costs (Forrester).
3. Investment Increase:
The global data lake market is projected to grow from $8.5 billion in 2020 to around $20 billion by 2026 (Mordor Intelligence).
4. Real-Time Analytics Focus:
45% of companies are implementing real-time data processing in their data lake strategies (Deloitte).
5. Integration with AI/ML:
70% of organizations using data lakes are also leveraging AI and ML (McKinsey).
Key Statistics
1. Data Volume Growth:
IDC estimates the global data sphere will reach 175 zettabytes by 2025, making data lakes essential.
2. Diverse Data Sources:
80% of organizations utilize multiple data sources, highlighting the need for data lakes (TDWI).
3. Improved Decision-Making:
Companies leveraging data lakes see a 20-30% improvement in decision-making speed (Harvard Business Review).
4. Operational Efficiency:
Organizations with mature data lake strategies report a 40% increase in operational efficiency (Gartner).
5. Cost Reduction:
Data lakes can reduce storage costs by up to 30% compared to traditional warehouses (Forrester).
Case Studies: How Business Leaders Take Benefits from Data Lakes Solutions
1. Netflix: Enhancing Customer Experience with Data Lakes
Industry: Entertainment & Streaming
Solution: Data Lake on AWS (Amazon Web Services)
Objective: To deliver personalized content recommendations and improve user experience.
Overview:
Netflix uses a data lake architecture to store massive amounts of raw, unstructured, and semi-structured data generated from over 238 million global subscribers. Data lakes allow Netflix to aggregate user activity data such as viewing history, preferences, and interactions across various devices. This data is critical for their machine learning models, which are used to optimize content recommendations and create personalized viewing experiences.
Benefits:
Personalized Content Recommendations: By analyzing data from different sources in a data lake, Netflix’s recommendation engine provides highly customized content to individual users, driving user engagement and reducing churn.
Real-time Analytics: Netflix uses its data lake to enable real-time analytics on viewer behavior, helping to optimize streaming quality, reduce buffering, and enhance overall service reliability.
Content Production Insights: Data lakes also help Netflix identify trends in viewing habits, which informs decisions on original content production, leading to the development of successful shows and movies tailored to audience preferences.
Impact:
Increased Customer Retention: Netflix’s data-driven recommendations have significantly improved user satisfaction, resulting in higher retention rates.
Efficient Content Investment: Data insights from the lake allow Netflix to make data-backed decisions on content investments, maximizing returns.
2. Airbnb: Leveraging Data Lakes for Advanced Data Science
Industry: Hospitality & Travel
Solution: Data Lake on Google Cloud
Objective: To streamline data science workflows and improve decision-making.
Overview:
Airbnb relies on its data lake to manage and analyze large-scale datasets generated from millions of guests and hosts around the world. Airbnb collects data on user searches, booking patterns, host reviews, and location preferences. The data lake serves as a foundation for the company’s data science initiatives, enabling teams to run experiments and deploy machine learning models that improve operational efficiencies.
Benefits:
Centralized Data Access: Airbnb’s data lake allows for the collection of diverse datasets, including structured and unstructured data from listings, reviews, and customer feedback. This enables seamless collaboration across departments such as marketing, operations, and customer service.
Improved Pricing Models: Data lakes help Airbnb run machine learning algorithms to optimize dynamic pricing models, ensuring that rental prices are competitive while maximizing revenue for hosts.
Fraud Detection: By analyzing large-scale data sets from transactions, Airbnb can detect patterns that indicate fraudulent activity, protecting both users and hosts from scams.
Impact:
Improved Host-Guest Matching: Airbnb's data-driven insights help match hosts with guests more accurately, enhancing the booking experience.
Operational Efficiency: Data lakes have enabled faster, more efficient data processing, allowing the company to scale and improve business decision-making.
3. Capital One: Transforming Banking with Data Lakes
Industry: Financial Services
Solution: Data Lake on AWS (Amazon Web Services)
Objective: To improve customer service, fraud detection, and operational efficiencies.
Overview:
Capital One, one of the leading financial institutions in the U.S., uses a data lake to collect and store customer transaction data, financial records, and other operational data. By leveraging AWS’s scalable storage solutions, Capital One has created a unified data environment to run advanced analytics and machine learning models.
Benefits:
Fraud Detection: The data lake enables real-time monitoring of transactions to identify suspicious activities. By running machine learning models on large datasets, Capital One can detect and prevent fraud with greater accuracy.
Personalized Banking: The data lake allows Capital One to analyze customer behavior and tailor banking services, such as recommending credit card products, offering financial advice, and adjusting credit limits based on user profiles.
Regulatory Compliance: Storing vast amounts of data in a secure, centralized data lake also helps Capital One meet regulatory requirements, ensuring that data is compliant with financial regulations like the GDPR and CCPA.
Impact:
Improved Fraud Prevention: Capital One has reduced fraudulent transactions by integrating data lakes with machine learning systems for better fraud detection and mitigation.
Enhanced Customer Experience: The ability to analyze customer interactions in real time has helped Capital One provide personalized banking solutions, leading to higher customer satisfaction and retention.
Conclusion
Data lakes offer an incredible opportunity for businesses to harness the power of their data. However, a poorly designed or managed data lake can quickly devolve into a costly and inefficient system. By following the right architecture, adhering to design principles, and implementing best practices, organizations can build a scalable, flexible, and efficient data lake that empowers analytics, innovation, and data-driven decision-making.
Hexaview Technologies offers data lake consulting services that empower businesses to efficiently manage and unlock the full potential of their data. With the increasing role of data in shaping strategic decisions, Hexaview Technologies tailored approach to building, optimizing, and maintaining data lakes ensures organizations can harness the power of big data for sustained growth and innovation.
Leveraging Hexaview's enterprise data lake consulting services can ensure that your data lake solution is optimized for your specific business needs, enabling you to transform raw data into actionable insights. Whether you’re looking to streamline data management, enhance analytics capabilities, or scale your infrastructure, Hexaview Technologies is here to guide you every step of the way.
About the Author
Ready to expand your global team?
Helping regulated enterprises modernize systems, adopt AI-first engineering, and deliver outcomes that pass audits the first time.
.svg)








%201.svg)
